
Meta ImageBind — это мультимодальная модель Meta AI, которая связывает разные типы данных в одном общем пространстве признаков: изображения, текст, аудио, глубину, тепловые данные и IMU. На практике это означает, что одна система может сопоставлять между собой разные «языки» восприятия и находить смысловые связи между ними. Официальное описание проекта доступно на странице ImageBind от Meta AI.
Для специалистов по компьютерному зрению, мультимодальному поиску и AI-интерфейсам ImageBind интересен тем, что модель не ограничивается только картинками и текстом. Она расширяет идею общего embedding-space и позволяет строить сценарии, где звук, изображение и сенсорные сигналы работают как взаимосвязанные источники информации.
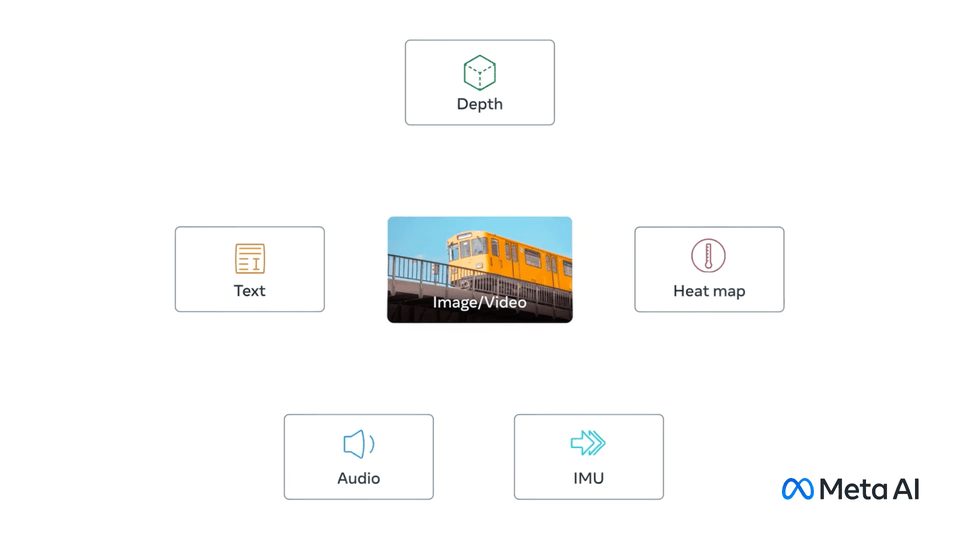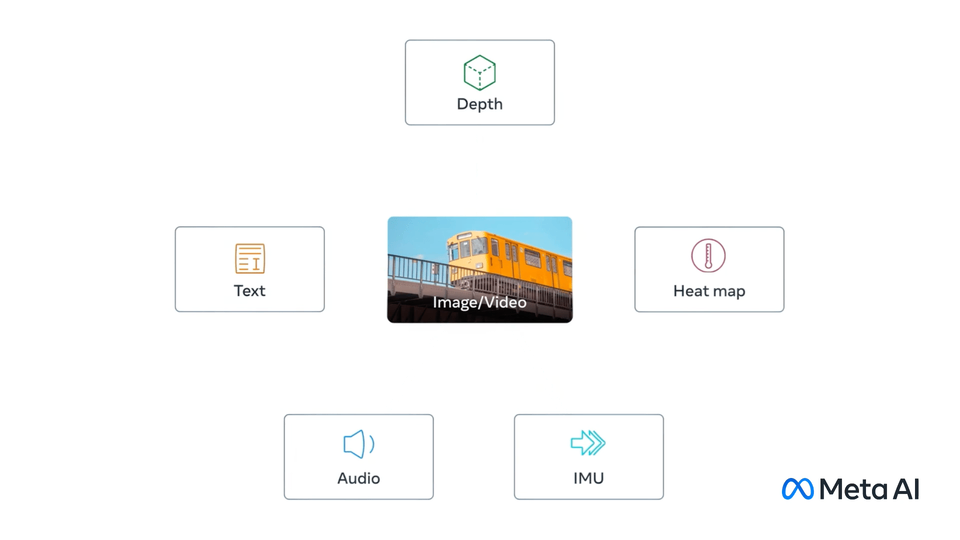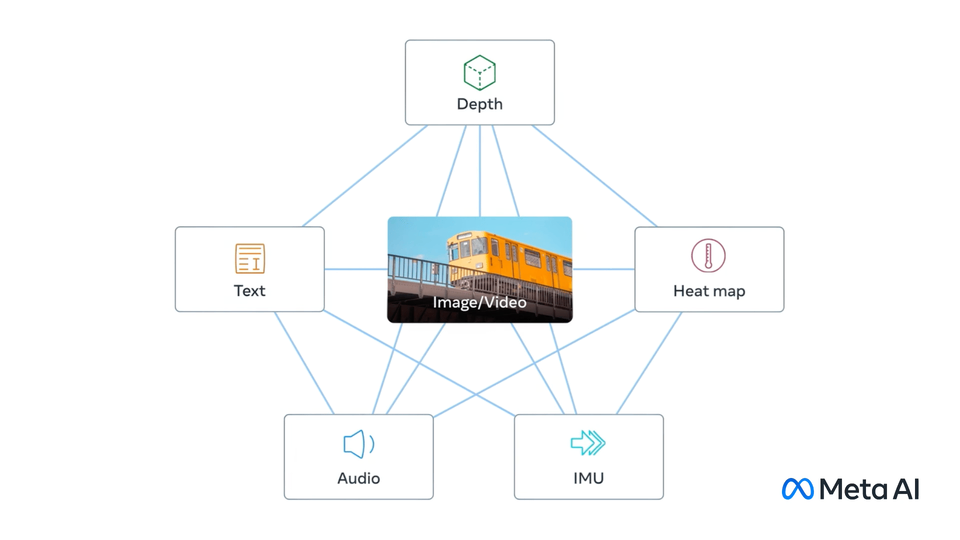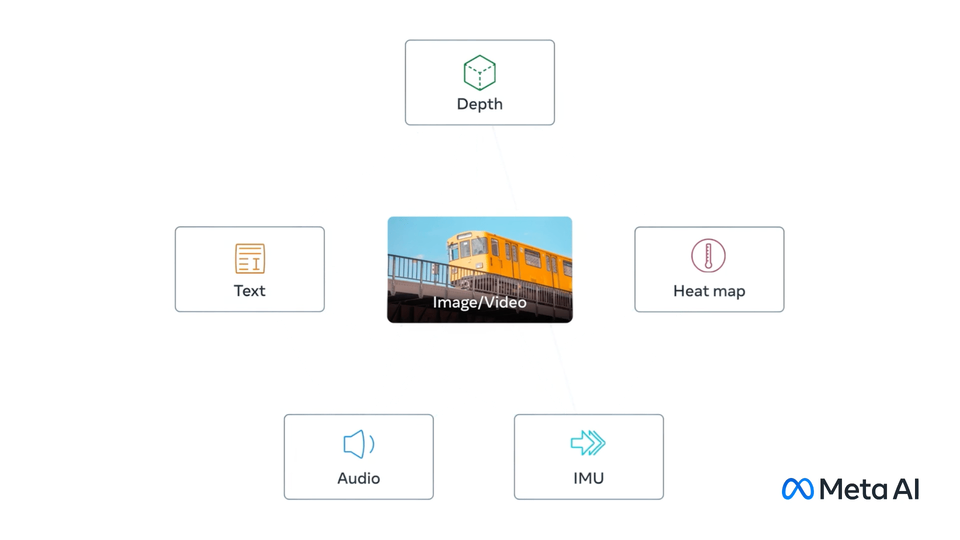
Официальная визуализация ImageBind: модель объединяет несколько модальностей в общее пространство представлений.
🧠 Что такое Meta ImageBind и почему о модели так много говорят?
ImageBind относится к классу мультимодальных foundation-моделей. Ее ключевая идея состоит в том, чтобы не обучать отдельные мосты между каждой парой модальностей, а привязать разные типы данных к общей точке отсчета через изображения. Такой подход заметно упрощает мультимодальное выравнивание и открывает новые сценарии поиска, классификации и генерации.
В исследовании Meta AI модель была представлена как система, которая умеет работать сразу с шестью модальностями. Это особенно важно для задач, где объект нужно понимать не только визуально, но и через звук, пространственную структуру сцены, тепловую карту или сигналы движения. Для AI-разработки это шаг к более «связанному» машинному восприятию.
ImageBind показывает, что единое пространство эмбеддингов может связывать несколько сенсорных модальностей даже без полного набора парных данных между всеми типами входов.
📌 Какие данные понимает ImageBind?
Одна из главных причин популярности Meta ImageBind — поддержка сразу нескольких типов входных данных. Это делает модель удобной не только для исследований, но и для прототипирования новых AI-продуктов.
- 🖼️ Изображения и видео — базовая визуальная модальность.
- 📝 Текст — описания, запросы, подписи и семантические подсказки.
- 🔊 Аудио — звуки природы, речь, шумы, акустические признаки событий.
- 📏 Depth — глубинные карты сцены.
- 🌡️ Thermal — тепловые данные.
- 📍 IMU — сигналы инерциальных датчиков движения.
Зачем это нужно? Например, система может сопоставить звук с изображением, а затем использовать найденное соответствие для поиска похожего контента. Такой подход полезен в робототехнике, XR, мультимодальном поиске, видеоаналитике и экспериментальных интерфейсах.
🚀 Где Meta ImageBind особенно полезен?
ImageBind интересен не только как исследовательская работа, но и как практический инструмент для построения прототипов. Модель особенно ценят за то, что она работает с единым embedding-space и помогает быстро проверять идеи без проектирования десятков отдельных связок между моделями.
- 🔍 Мультимодальный поиск — поиск изображения по тексту, звуку или комбинированному запросу.
- 📊 Zero-shot классификация — определение класса без отдельного обучения под каждую задачу.
- 🎛️ Композиция смыслов — объединение признаков из разных модальностей.
- 🤖 Робототехника и embodied AI — связывание наблюдений камеры, звука и движения.
- 🧪 Исследовательские пайплайны — тестирование новых мультимодальных архитектур.
Проблема: многие мультимодальные системы сложно масштабировать, потому что для каждой новой модальности приходится заново настраивать логику согласования. Решение: ImageBind предлагает общее пространство представлений, куда можно проецировать разные типы данных. Результат: разработчики быстрее собирают прототипы поиска, сопоставления и классификации на одной модели.
Главная ценность ImageBind не в «магии шести входов», а в том, что модель делает мультимодальные связи более инженерно управляемыми.
❓ Чем ImageBind отличается от обычных vision-language моделей?
Классические vision-language модели чаще всего связывают только изображение и текст. Это уже мощный формат, но он ограничен двумя каналами восприятия. Meta ImageBind идет дальше и добавляет еще несколько источников информации, сохраняя единое пространство признаков.
Именно поэтому модель часто упоминают в контексте следующего этапа мультимодального AI. Она не просто «понимает картинку по описанию», а пытается связать визуальный объект с тем, как он звучит, как выглядит в тепловом спектре или как воспринимается сенсорами движения.
| Параметр | Обычная vision-language модель | Meta ImageBind |
|---|---|---|
| Количество модальностей | Обычно 2 | 6 |
| Основной сценарий | Изображение ↔ текст | Изображение, текст, аудио, depth, thermal, IMU |
| Сильная сторона | Captioning, retrieval, VLM-задачи | Более широкая мультимодальная связность |
| Подходит для | Контент-анализ, поиск, описания | AI-исследований, embodied AI, мультимодальных прототипов |
🖼️ Как работает Meta ImageBind на концептуальном уровне?
Если упростить архитектурную идею, модель кодирует каждый тип входа в вектор одинаковой логики, после чего сравнивает близость между векторами. Чем ближе эмбеддинги, тем выше вероятность смыслового соответствия между объектами. Именно поэтому можно сопоставлять, например, лай собаки, текстовое описание собаки и ее изображение.
Такой подход особенно хорош для retrieval-задач. Вместо жестких правил система использует расстояние в embedding-space. Аналитики часто рассматривают это как удобный фундамент для систем рекомендаций, мультимодального поиска и zero-shot пайплайнов, о чем мы подробно писали в материале про оптимизацию скорости загрузки AI-интерфейсов и в статье про архитектуру мультимодальных моделей.

Схематическое представление работы ImageBind: разные модальности проецируются в единое embedding-пространство.
🛠️ Пошаговая инструкция: как начать работать с Meta ImageBind
Ниже — базовый маршрут для тех, кто хочет попробовать ImageBind на практике. Он подходит для ML-инженеров, исследователей и разработчиков, знакомых с Python и PyTorch.
- Откройте официальный репозиторий. Найдите проект ImageBind на GitHub и ознакомьтесь с README, зависимостями и лицензией.
- Подготовьте окружение. Создайте отдельное Python-окружение и установите PyTorch, затем зависимости проекта.
- Установите ImageBind. В стандартном варианте используется установка пакета из репозитория через pip.
- Выберите модальности для теста. Проще всего начать с текста, изображений и аудио.
- Подготовьте данные. Нужны локальные пути к файлам и короткие текстовые промпты для сравнения.
- Загрузите предобученную модель. Обычно стартуют с варианта imagebind_huge.
- Извлеките эмбеддинги. После преобразования входов модель возвращает представления по каждой модальности.
- Сравните сходство. Для этого вычисляют similarity между эмбеддингами и смотрят, какие пары ближе.
- Постройте прототип. После первого теста можно собрать поиск по аудио, zero-shot классификацию или мультимодальную галерею.
Сохраните этот список себе: он особенно удобен, когда нужно быстро поднять демо и проверить идею без долгой интеграции. Для первого запуска не стоит усложнять сценарий — достаточно пары изображений, нескольких текстовых описаний и 2–3 аудиофайлов.
Лучший способ познакомиться с ImageBind — не читать о нем слишком долго, а сразу проверить близость эмбеддингов на нескольких простых примерах.
✅ Чек-лист перед первым запуском ImageBind
- ☑️ Подготовлено Python-окружение с совместимой версией PyTorch.
- ☑️ Установлены зависимости проекта.
- ☑️ Есть 2–3 тестовых изображения и короткие текстовые описания.
- ☑️ Подготовлены аудиофайлы для сравнения.
- ☑️ Понимание, какую задачу вы тестируете: retrieval, классификацию или исследование эмбеддингов.
- ☑️ Учтено, что модель в первую очередь ориентирована на исследовательское использование.
Сохраните этот список себе, чтобы не возвращаться к подготовительным шагам каждый раз при новом эксперименте.
⚠️ Какие ограничения важно учитывать?
Несмотря на сильную идею и впечатляющую демонстрацию, Meta ImageBind не стоит воспринимать как готовое универсальное решение для любого продакшена. В model card прямо подчеркивается исследовательский характер модели, а также возможные ограничения, связанные с качеством данных и смещениями.
Эксперты обычно обращают внимание на несколько моментов:
- Лицензия и сценарий использования. Перед коммерческим применением нужно отдельно проверить условия лицензирования.
- Bias и ограничения данных. Модель наследует свойства исходных датасетов и начальных энкодеров.
- Языковые ограничения. Текстовая часть в первую очередь ориентирована на английский язык.
- Необходимость валидации. Для прикладных задач результаты стоит перепроверять на собственной выборке.
🎯 Для кого подходит Meta ImageBind?
ImageBind особенно полезен тем, кто создает или исследует мультимодальные системы. Это хороший выбор для тех случаев, где важно быстро проверить гипотезу, построить retrieval-пайплайн или понять, как разные модальности соотносятся между собой на уровне признаков.
В первую очередь модель будет полезна:
- ML-инженерам и исследователям компьютерного зрения;
- командам, работающим с мультимодальным поиском;
- разработчикам embodied AI и робототехники;
- специалистам по видеоаналитике и AI-прототипированию;
- тем, кто изучает foundation-модели Meta AI.
📍 Стоит ли пробовать ImageBind прямо сейчас?
Если задача связана с мультимодальными эмбеддингами, то попробовать модель определенно стоит. Она не заменяет все существующие мультимодальные решения, но отлично подходит как исследовательская база и как инструмент для быстрых proof-of-concept. Особенно ценен тот факт, что система уже имеет открытый код и демонстрационные материалы.
Теперь, когда вы понимаете логику работы модели, самое время перейти к практике: откройте репозиторий, возьмите небольшой набор данных и проверьте, как Meta ImageBind связывает текст, звук и изображения в вашем сценарии.
{
«@context»: «https://schema.org»,
«@type»: «Article»,
«headline»: «Meta ImageBind: подробный обзор модели и инструкция по взаимодействию»,
«author»: {
«@type»: «Organization»,
«name»: «OpenAI»
},
«publisher»: {
«@type»: «Organization»,
«name»: «OpenAI»
},
«datePublished»: «2026-03-06»,
«dateModified»: «2026-03-06»,
«description»: «Подробная HTML-статья о Meta ImageBind: что это за мультимодальная модель, как она работает, где применяется и как начать использовать ее на практике.»,
«image»: [
«https://user-images.githubusercontent.com/8495451/236859695-ffa13364-3e39-4d99-a8da-fbfab17f9a6b.gif»
],
«mainEntityOfPage»: «https://ai.meta.com/research/publications/imagebind-one-embedding-space-to-bind-them-all/»
}