
Stability AI StableLM — семейство открытых языковых моделей, ориентированных на практическое применение: генерацию текста, помощь в кодинге, суммаризацию, ответы на вопросы и работу в чат-режиме. В актуальной линейке особое внимание привлекает Stable LM 2: компактная версия 1.6B и более мощная 12B, обученные на большом объеме данных и поддерживающие многоязычные сценарии.
Официальные материалы и модели доступны в открытом доступе: новости и анонсы Stability AI, репозиторий серии StableLM, а также страницы моделей на Hugging Face.
Полезная отправная точка: https://stability.ai/news/introducing-stable-lm-2

Пример сравнения Stable LM 2 1.6B с популярными малыми моделями по бенчмаркам.
🧠 Что такое StableLM и чем отличается Stable LM 2?
Под брендом StableLM Stability AI развивает линейку языковых моделей, где упор делается на доступность, прозрачность и возможность развертывания на разном «железе» — от локальных машин до серверов. Внутри семейства встречаются разные поколения и варианты, а Stable LM 2 — это новая серия, в которой заметно улучшены качество и практичность при сохранении фокуса на эффективности.
Важная идея: не существует “одной лучшей” модели для всех задач. Специалисты обычно выбирают версию под сценарий — для локального запуска, для RAG-поиска, для чат-ассистента, для прототипирования или для тонкой настройки (fine-tuning).
Эксперты по внедрению LLM часто подчеркивают: меньшая модель при грамотных промтах и хороших данных в RAG может дать результат, сравнимый с «большими», но при существенно меньшей стоимости.
Ключевые особенности Stable LM 2
- ⚡ Эффективность: версии 1.6B и 12B рассчитаны на баланс скорости и качества.
- 🌍 Многоязычность: заявлена поддержка нескольких европейских языков (в зависимости от версии и настройки).
- 🧩 Варианты “base” и “instruct/chat”: базовые модели для дообучения и инструкционные — для диалогов.
- 🧰 Инструментальные сценарии: у инструкционных вариантов акцент на полезном “ассистентском” поведении (включая tool use / function calling в релизных обновлениях).
🔍 1.6B или 12B: какую версию выбрать?
Частый вопрос: зачем брать 12B, если есть 1.6B? Ответ прагматичный — все упирается в качество и ресурсы. Если нужен быстрый локальный ассистент, прототип или массовая генерация коротких текстов — 1.6B нередко оказывается «золотой серединой». Если же важны более сложные рассуждения, устойчивость к неоднозначным запросам и лучшее следование инструкциям — 12B обычно выигрывает.
При этом аналитики напоминают: на реальных задачах разница часто проявляется не только в параметрах, а в связке
промт → контекст → инструменты → проверка фактов. Хотите меньше “галлюцинаций”? Тогда важны RAG, ограничения формата ответа и пост-валидация.
| Критерий | Stable LM 2 1.6B | Stable LM 2 12B |
|---|---|---|
| Сценарии | Локальный запуск, быстрые ответы, черновики, классификация | Более сложные инструкции, длинные ответы, RAG-ассистент, tool use |
| Ресурсы | Ниже требования к VRAM/ОЗУ, проще встраивать в продукты | Выше требования, чаще нужен GPU/квантизация |
| Качество | Хорошо для «узких» задач и шаблонов | Сильнее в обобщении, следовании инструкциям и сложных диалогах |
| Тюнинг | Быстрее и дешевле дообучать (LoRA/QLoRA) | Тюнинг дороже, но потенциал выше |
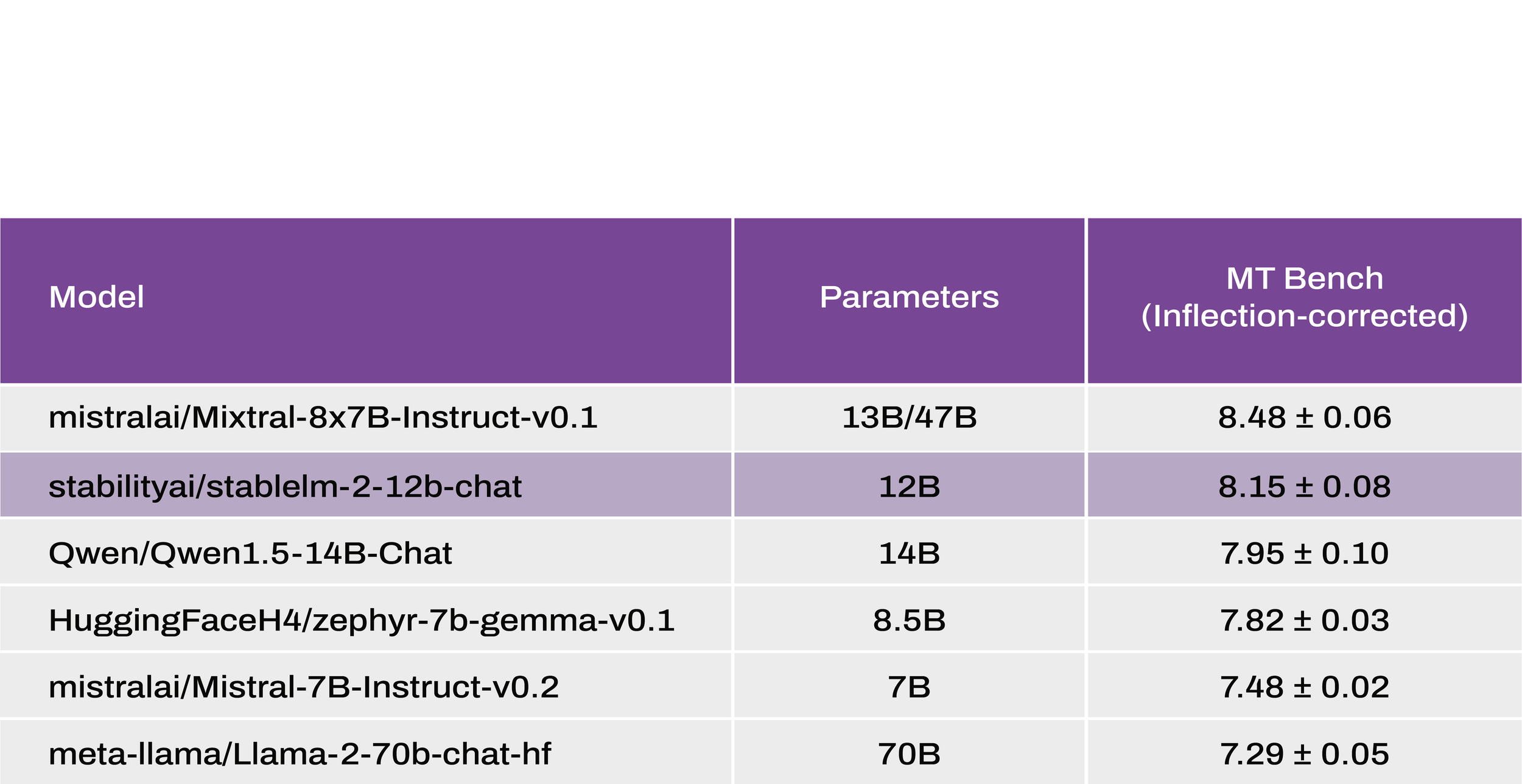
Иллюстрация сравнений Stable LM 2 12B на популярных тестах качества диалоговых моделей.
🧩 Как устроено взаимодействие с StableLM
В практических интеграциях обычно есть три уровня взаимодействия:
локальный запуск (для приватности и экономии), серверное развертывание (для команды/продукта) и
гибрид (локально + облако на пиковой нагрузке). Для большинства задач достаточно выбрать правильный тип модели:
base — если планируется дообучение, и instruct/chat — если нужен ассистент «из коробки».
Практика внедрения показывает: половина успеха — это не выбор LLM, а правильная постановка задачи и формат ответа (структура, ограничения, проверка фактов).
🧨 Проблема — Решение — Результат (на примере поддержки клиентов)
Проблема: ответы службы поддержки нестабильны по качеству, операторы тратят время на повторяющиеся вопросы, а база знаний «размазана» по документам.
Решение: использовать StableLM как “черновик-ассистент” + подключить RAG (поиск по базе знаний) + добавить строгий шаблон ответа и запрет на выдумывание фактов.
Результат: сокращается время на подготовку ответа, повышается единообразие, а спорные кейсы уходят на человека — и вы контролируете качество.
🛠️ Пошаговая инструкция: запуск StableLM через Transformers (локально)
Ниже — универсальная схема, которую специалисты используют для быстрого старта. Если у вас ограниченные ресурсы, начните с Stable LM 2 1.6B, а затем переходите к 12B.
- Выберите модель: base для дообучения или instruct/chat для диалога.
- Проверьте лицензию: для коммерческого использования уточните условия у Stability AI.
- Установите окружение: Python, PyTorch, Transformers, Accelerate (и при необходимости bitsandbytes).
- Загрузите веса с Hugging Face и запустите генерацию текста на тестовом промте.
- Включите ограничения: max_new_tokens, temperature, top_p, stop-токены (если поддерживаются).
- Подключите RAG при работе с фактами и документацией, чтобы уменьшить “галлюцинации”.
- Профилируйте: скорость токенов/сек, потребление памяти, стабильность на длинном контексте.
- ✅ Сохраните этот список себе: он пригодится для любого open-source LLM-развертывания.
- 📌 Если планируется продакшн, добавьте: логирование, лимиты запросов, фильтры безопасности и тестовый набор промтов.
📌 Практические советы по промтам для StableLM
Чтобы модель отвечала предсказуемо, эксперты рекомендуют задавать роль, контекст и формат.
Например: «Сгенерируй 5 вариантов, каждый — не более 2 предложений» или «Ответ дай списком, без воды».
- 🧠 Формат: заранее задайте структуру ответа (список, таблица, чек-лист).
- 🔍 Факты: просите ссылаться на предоставленный контекст (документ/выдержка), а не на “память”.
- ⚖️ Тон: “экспертно-нейтральный” часто лучше продающего — меньше риска ошибочных утверждений.
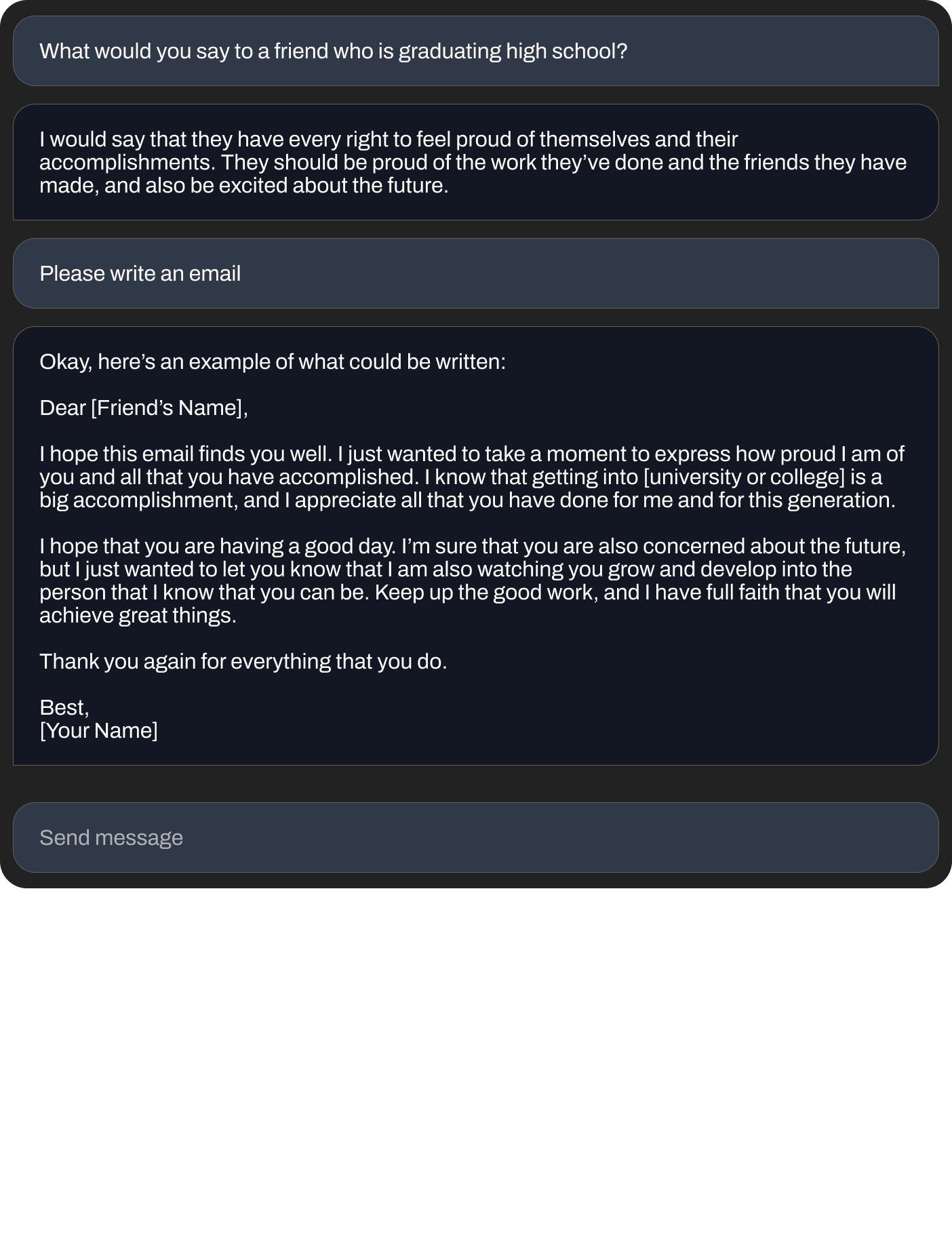
Пример диалогового взаимодействия: запрос → развернутый ответ в заданном формате.
🚀 Быстрый старт через Ollama: когда нужно “поставил и работает”?
Если вы хотите минимальную сложность, удобный путь — локальные рантаймы, где модель можно запустить одной командой и сразу дергать из терминала или через локальный HTTP.
Такой подход особенно полезен, когда нужно быстро проверить гипотезу: «подходит ли StableLM под мой кейс?».
Здесь важно помнить: качество зависит от выбранной версии (base/chat), контекста и ограничений генерации. Поэтому не стесняйтесь тестировать 10–20 типовых запросов из вашей реальной работы — так решение будет не «по ощущениям», а по метрикам.
Хотите понять, «потянет ли» модель ваш кейс? Возьмите реальные запросы пользователей, добавьте требования к формату ответа и прогоните A/B-тест между 1.6B и 12B.
🧯 Безопасность, ограничения и ответственность
Как и другие LLM, StableLM может ошибаться, уверенно “додумывать” факты и иногда генерировать нежелательный контент. Поэтому при внедрении специалисты обычно добавляют:
фильтры, ограничения на темы, модерацию и обязательную проверку для критичных сценариев (медицина, финансы, право).
Особенно важно: при коммерческом использовании нужно внимательно изучить лицензирование конкретных весов и условия распространения продукта. У разных релизов и вариантов серии StableLM встречаются разные лицензии и ограничения.
✅ Чек-лист внедрения StableLM в продукт
- 📦 Выбрана версия: 1.6B для скорости или 12B для качества.
- 🔐 Проверены лицензии и условия коммерческого применения.
- 🧾 Определен формат ответа (JSON/маркированный список/таблица) и добавлены валидаторы.
- 🔎 Подключен RAG для фактов и документации (если нужно).
- 🧪 Подготовлен набор тестов: 50–200 реальных запросов + метрики качества.
- 🛡️ Настроены фильтры безопасности и эскалация на человека.
Теперь, когда вы понимаете различия версий и базовую схему запуска, самое практичное действие — взять 10 реальных задач и прогнать их на 1.6B и 12B.
Так вы быстро увидите, где нужна мощность, а где выигрывает скорость и цена.
Также рекомендуем: …об этом мы подробно писали в статье про настройку RAG для базы знаний, а также в материале про оптимизацию скорости загрузки AI-сервиса.
{
«@context»: «https://schema.org»,
«@type»: «Article»,
«headline»: «Stability AI StableLM (Stable LM 2): подробный обзор и пошаговая инструкция по взаимодействию»,
«description»: «Подробный разбор Stability AI StableLM (Stable LM 2): версии 1.6B и 12B, возможности, лицензирование и пошаговая инструкция запуска и интеграции.»,
«author»: {
«@type»: «Organization»,
«name»: «Редакция сайта»
},
«publisher»: {
«@type»: «Organization»,
«name»: «Редакция сайта»
},
«datePublished»: «2026-02-28»,
«dateModified»: «2026-02-28»,
«image»: [
«https://images.squarespace-cdn.com/content/v1/6213c340453c3f502425776e/efd2298d-c95a-4fef-a6d3-8e118c5774d3/Stable_LM_2_1.6B_Open_LLM_Leaderboard.png»,
«https://images.squarespace-cdn.com/content/v1/6213c340453c3f502425776e/d4b26d33-bdca-4559-9295-7ba65f78a9ab/Stable%2BLM%2B-%2BChart%2B7%2B-%2BMT-Bench_3_Padded_3.png»,
«https://images.squarespace-cdn.com/content/v1/6213c340453c3f502425776e/1681917220997-65CT7HXKJC2SO0J4JY4U/example%2B1.png»
],
«mainEntityOfPage»: {
«@type»: «WebPage»,
«@id»: «https://stability.ai/news/introducing-stable-lm-2»
}
}

